
Anthropic says the campaigns were engineered to extract advanced reasoning, coding, and agentic capabilities from its frontier systems using AI model distillation. Inside a lab, distillation is routine smaller models learn from larger ones all the time. But Anthropic’s position is blunt: when you point that technique at a rival’s model without permission, it stops being research and starts looking like systematic capability theft.
What Happened: Claude Distillation Attacks at Scale
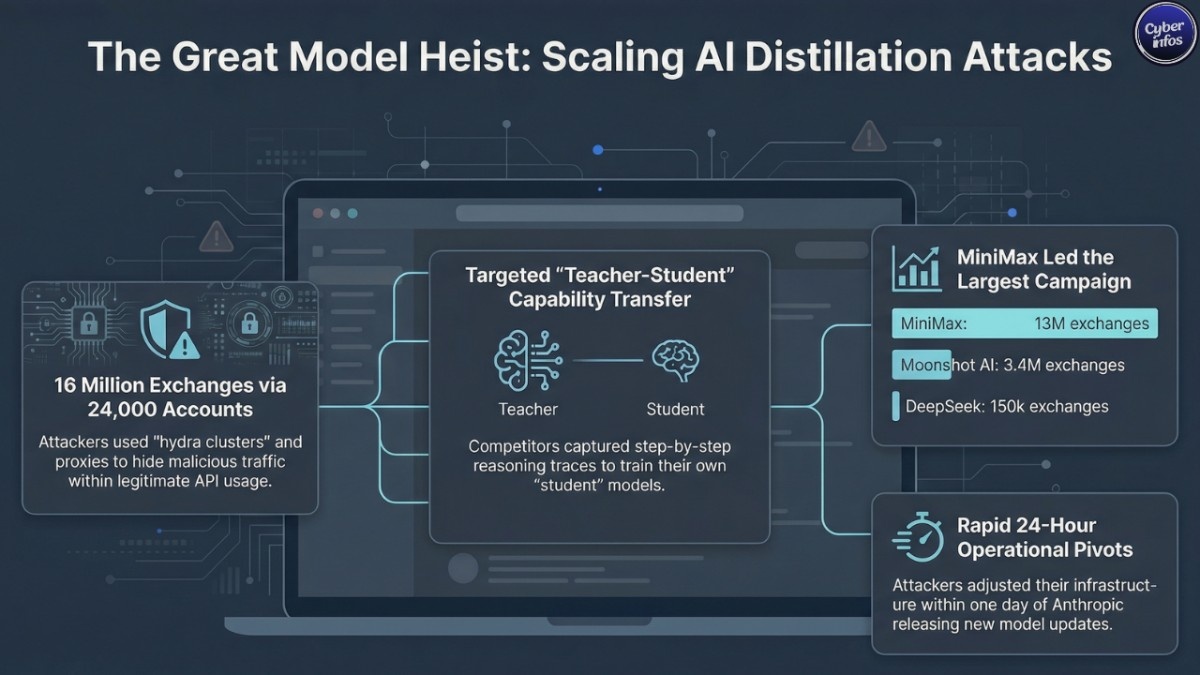
Anthropic stated that three Chinese AI labs DeepSeek, Moonshot AI, and MiniMax conducted coordinated distillation campaigns targeting its Claude models.
The San Francisco-based firm outlined operations that allegedly:
- Used approximately 24,000 fraudulent accounts
- Generated over 16 million exchanges
- Circumvented regional access restrictions through third-party proxy services
- Extracted advanced reasoning traces and model outputs
That volume alone should raise eyebrows. Sixteen million exchanges isn’t background noise it’s infrastructure.
Campaign Breakdown
DeepSeek
- ~150,000 exchanges
- Focused on advanced reasoning and rubric-based grading
- Prompts designed to elicit step-by-step chain-of-thought reasoning
Moonshot AI (Kimi models)
- ~3.4 million exchanges
- Targeted agentic reasoning, coding, computer-use agents, and computer vision
- Reconstructed Claude’s reasoning traces
MiniMax
- ~13 million exchanges (largest campaign)
- Targeted agentic coding and tool-use orchestration
- Pivoted traffic within 24 hours after Anthropic released a new model
That last detail stands out. A 24-hour pivot after a model update suggests operational monitoring not casual experimentation.
Anthropic attributed the campaigns with “high confidence,” pointing to IP correlations, metadata patterns, infrastructure fingerprints, and corroboration from industry partners. In other words, this wasn’t a guess. It was a forensic call.
The disclosure also comes weeks after OpenAI reportedly warned U.S. lawmakers about similar efforts targeting ChatGPT. The pattern, if accurate, isn’t isolated.
How the Attack Works: Understanding AI Model Distillation Abuse
Distillation, by itself, is a legitimate AI training method. A smaller “student” model learns by observing the outputs of a larger “teacher” model. Frontier labs use this constantly to create faster, cheaper variants of their own systems.
But in a Claude distillation attack, the “student” model doesn’t belong to the same lab. It belongs to a competitor.
Here’s the simplified mechanics:
- Attackers send carefully structured prompts to the target model.
- They capture not just the final answers, but the reasoning patterns behind them.
- Those outputs become training data for their own model.
- Over time, the student model learns to replicate comparable performance.
Think of it this way: you hire a world-class tutor to solve tens of thousands of exam questions. You record every explanation. Then you use that archive to train your own replacement tutor. At scale, that becomes capability transfer.
Anthropic said the actors relied on “hydra clusters” large networks of fraudulent accounts combined with commercial proxy resellers that blended distillation traffic with legitimate API usage. That blending effect matters. When malicious activity hides inside normal customer behavior, detection gets murky fast.
The company is now deploying classifiers to detect chain-of-thought elicitation attempts and behavioral fingerprinting systems to flag coordinated activity. But here’s the uncomfortable truth: inference access is, by design, open enough to be useful. And that openness is precisely what makes this kind of abuse possible.
Who Is at Risk In Claude Distillation Attacks?
This incident centers on AI labs. But the blast radius is wider than it looks.
Organizations potentially affected include:
- AI model providers distributing systems via APIs
- Cloud providers hosting frontier models
- Enterprises integrating LLMs into workflows
- Governments concerned about AI export controls
- Organizations handling sensitive prompts or proprietary data
If distilled models are deployed without built-in safeguards, they may:
- Omit safety filters
- Enable misuse in cyber operations
- Lower barriers for dual-use capabilities
For enterprises evaluating foreign AI models or open-source derivatives, this raises hard questions about LLM supply chain risk. Where did this model’s capability really come from? And were guardrails stripped out along the way?
Most organizations won’t ask those questions until procurement is already done.
That’s the part nobody is talking about.
Expert Analysis: Why This Matters
The scale of the alleged Claude distillation attacks 16 million exchanges makes this one of the largest publicly disclosed model extraction efforts to date.
Model extraction and API abuse aren’t new. Academic researchers demonstrated practical attacks against ML-as-a-service platforms as far back as 2021 and 2022. But this case, if the allegations hold, represents something different: industrial-scale replication of frontier LLM capabilities. And the timing isn’t accidental.
Anthropic reiterated support for U.S. export controls on advanced AI chips, arguing that limiting hardware access constrains both direct training and the scale of illicit distillation. Critics counter that distillation can partially sidestep compute restrictions by transferring capability instead of rebuilding it from scratch.
So which is it? Hardware choke points or digital leakage?
If substantiated, the incidents expose a structural weakness in API-delivered AI: every inference call can double as training data for someone else.
The broader policy question becomes unavoidable: Can frontier AI capabilities truly be protected in a globally accessible API economy?
What You Should Do Right Now
1. Monitor API Usage Patterns
- High-volume structured prompting
- Repeated reasoning extraction queries
- Cross-account traffic similarities
2. Rate-Limit and Segment Access
- Strict per-account rate limits
- Tiered access models
- Behavioral fingerprinting
3. Protect Chain-of-Thought Outputs
- Output filtering
- Redacted reasoning modes
- Controlled evaluation sandboxes
4. Vet Third-Party AI Providers
- Conduct supply chain risk assessments
- Evaluate model provenance
- Review compliance with export and sanctions laws
5. Strengthen Identity Verification
- Institutional validation
- Stronger KYC controls
- Payment method anomaly detection
6. Track Regulatory Developments
- AI export controls
- Cross-border AI governance rules
- National AI security frameworks
Final Thoughts
The alleged Claude distillation attacks expose a fragile fault line in the AI ecosystem: when powerful models are delivered through APIs, they don’t just serve users. They can quietly serve competitors.
For enterprises, this is a wake-up call on LLM security risks and supply chain integrity. For policymakers, it complicates the logic of export controls in a world where capability can be siphoned digitally, one API call at a time.
The real question isn’t whether model extraction will continue. It will. The question is whether organizations will detect it early or discover it only after their competitive edge has already been distilled away.